
Trading Algoritmico
“Produrre previsioni di alta qualità non è un problema facile né per le macchine né per la maggior parte degli analisti. Abbiamo osservato due temi principali nella pratica della creazione di una varietà di previsioni aziendali: le tecniche di previsione completamente automatiche possono essere fragili e sono spesso troppo inflessibili per incorporare ipotesi o euristiche utili. Gli analisti che possono produrre previsioni di alta qualità sono abbastanza rari perché la previsione è un’abilità specializzata nella scienza dei dati che richiede una notevole esperienza!”
Dal sito web di Facebook Prophet. In questo progetto utilizzeremo l’algoritmo Neural Prophet per la previsione del cross EUR/CHF. Per la trattazione dell’argomento si farà uso del software di programmazione Python in ambiente Jupiter Notebook.
[wcr]
Un mondo di profeti
Quando a gennaio, all’inizio di questa avventura divulgativa, abbiamo volute introdurre i concetti di previsione abbiamo fatto riferimento, con approccio provocatorio, a coloro che soprattutto nel passato pretendevano di prevedere il futuro basandosi su presunte doti magiche, segno di benevolenza divina, che permetteva loro di affermarsi nelle società del tempo incutendo rispetto e timore. Con il tempo e con il progresso scientifico si è dimostrato che i poteri paranormali previsionali erano fallimentari per almeno due motivi. Uno, erano statisticamente non affidabili, due, allorquando validi, erano giudicati tali da una predisposizione mentale a rendere le previsioni verosimili. Fare previsioni significa considerare tutte le caratteristiche (nello spazio e nel tempo) di un fenomeno passato, assegnare ad ognuna di esse un peso di influenza, combinarle tra loro e contestualizzarle ad una situazione futura. Posso prevedere con certezza pressoché assoluta che domani avremo un’alba e un tramonto, abbastanza bene se la giornata sarà piovosa, nuvolosa o soleggiata, un po’ meno se devo prevedere dove trovare parcheggio in centro città (tanto meno se non conosco la zona). La previsione è imprescindibile dall’esperienza passata, ma la stessa non ne è garanzia di accuratezza. Come nei teoremi matematici potremmo dire che, a meno di essere sicuro di aver considerato tutte (ma proprio tutte) le variabili, l’esperienza passata è condizione necessaria ma non sufficiente per la previsione.
Questo è vero a tutti i livelli, dai nostri comportamenti di fronte a determinate situazioni di cui abbiamo esperienza, alle strategie geopolitiche che prendono spunto dalla storiografia, dalle analisi e previsioni di vendita di un’attività commerciale, al classico esempio noto a tutti gli studiosi di machine learning sulla potenziale solvibilità di un cliente bancario. Quando parliamo di previsioni di prezzo e andamento di un prodotto finanziario tentiamo di dare una interpretazione di come quel fenomeno, già prodotto risultante di previsioni fatte nel passato (il mercato), possa evolversi sulla base di pattern storici. Un problema fondamentale è quello di determinare quale sia il migliore intervallo temporale tra il presente e il passato per elaborare la previsione, e fino a quando. Se per esempio il trader graficista vuole una previsione giornaliera, deve considerare l’andamento dell’ultimo mese, dell’ultima settimana o dell’ultimo anno?
FACEBOOK PROPHET
Facebook ha sviluppato il software previsionale Prophet disponibile per applicazioni sia in Python che in R. Fornisce parametri intuitivi che sono facili da modulare per cui anche chi non ha una profonda esperienza nei modelli di previsione in serie temporali può usarlo per generare previsioni significative per una vasta varietà di problemi.
È un modello di regressione su modelli che presentano carattere stagionale particolarmente robusto in caso di dati mancanti, spostamenti di tendenza, e nella gestione degli outlier.
Prophet utilizza un modello di serie temporale scomponibile con tre componenti principali del modello: tendenza, stagionalità e vacanze. Sono combinati nella seguente equazione:
y(t)= g(t) + s(t) + h(t) + εt
g(t): curva di crescita lineare o logistica per modellare i cambiamenti non periodici nelle serie temporali
s(t): cambiamenti periodici (ad esempio stagionalità settimanale/annuale)
h(t): effetti delle vacanze (fornite dall’utente) con orari irregolari
εt: il termine di errore tiene conto di qualsiasi cambiamento insolito non contemplato dal modello
Usando il tempo come regressore, Prophet inquadra il problema della previsione come un esercizio di adattamento della curva piuttosto che guardare esplicitamente la dipendenza basata sul tempo di ogni osservazione all’interno di una serie temporale. Prophet e la sua evoluzione Neural Prophet vengono considerati come il ponte di collegamento tra le pure tecniche di analisi delle serie temporali e il deep learning (vedi figura 1).

NEURAL PROPHET su EUR/CHF
Seguendo il solito principio di costruzione di un codice di machine learning [1], partiamo con l’importazione delle librerie di gestione tabelle e grafica.
import pandas_datareader.data as web
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
STEP 1 – Importazione e lettura dati
Procediamo con l’impostazione delle funzioni che ci permettono di leggere i valori del cross Euro/Franco Svizzero con ticker EURCHF=X che vogliamo analizzare:
pip install yfinance

Che da l’output visibile in figura 2, quello che ci permette di installare e utilizzare l’algoritmo Neural Prophet.
pip install neuralprophet
STEP 2 – Elaborazione, trasformazione e organizzazione dati
In questa fase trasformiamo i dati in maniera tale che gli stessi possano essere gestiti dall’algoritmo neuralprophet che utilizzeremo.

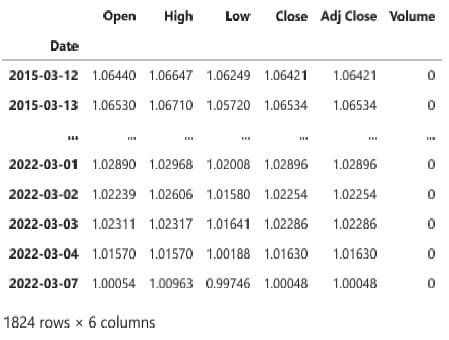
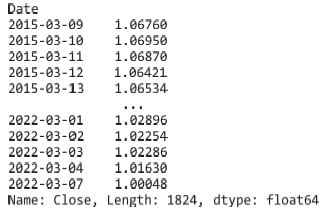
L’ultima riga di codice ci darà la possibilità d visualizzare la nuova struttura dati (vedi figura 3), e il suo andamento grafico con le funzioni di plotting (vedi figura 4).
Per utilizzare NeuralProphet dobbiamo operare una ulteriore trasformazione del nostro dataframe eseguendo le seguenti linee di codice :

Che restituisce l’output visibile in figura 5.

STEP 3 – Definizione del modello
Importiamo la libreria che ci permetterà di implementare neuralprophet ed eseguire le operazioni per esso necessarie con le seguenti istruzioni.
from neuralprophet import NeuralProphet
STEP 4 – Addestramento del modello
Con NeuralProphet l’addestramento del modello viene compiuto con le semplici line di codice che seguono dove indichiamo i nostri parametri (tra gli altri notiamo il periodo in cui vogliamo la previsione con n_forecast = periodo previsionale di 30 giorni),
m = NeuralProphet(
n_forecasts=30,
n_lags=60,
n_changepoints=50,
yearly_seasonality=True,
weekly_seasonality=False,
daily_seasonality=False,
batch_size=64,
epochs=100,
learning_rate=1.0,
)
STEP 5 – Valutazione di affidabilità del modello
Come sempre dobbiamo valutare la bontà del nostro modello e capire quando dopo diverse iterazioni di addestramento i valori convergono e diventano stabili per iterazioni successive (vedi figura 6)
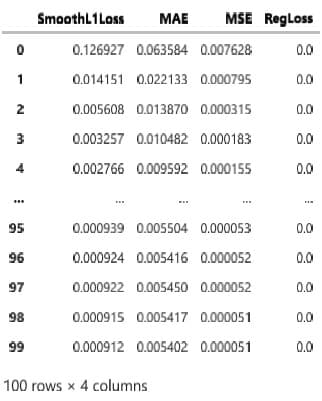
metrics = m.fit(dataprophet, freq=”D”)
metrics
Di cui possiamo vedere anche una rappresentazione grafica in figura 7.


STEP 6 – Previsione
Avendo costruito il modello ed avendo appurato la sua precisione, se accettabile, procediamo con la previsione futura, a 30 giorno dopo l’ultima data disponibile nel nostro dataset chiamato dataprophet e cioé 7 marzo 2022.
future = m.make_future_dataframe(dataprophet, periods=30, n_historic_predictions=len(roughdata))
#we need to specify the number of days in the future
prediction = m.predict(future)
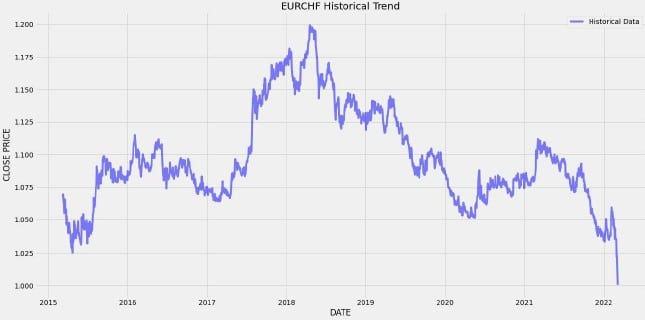
In questo modo, operando alcune trasformazioni e lanciando la funzione di plotting in figura 8a abbiamo il grafico in figura 9.
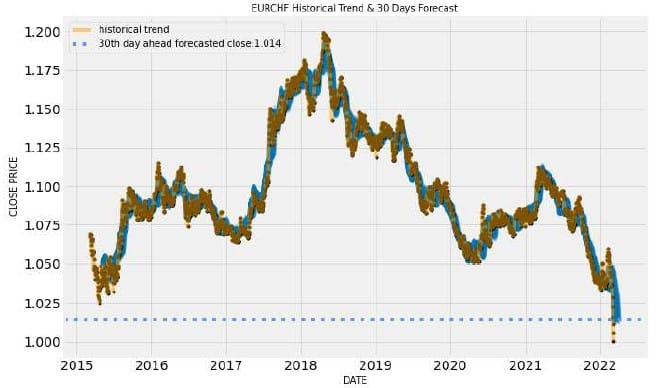
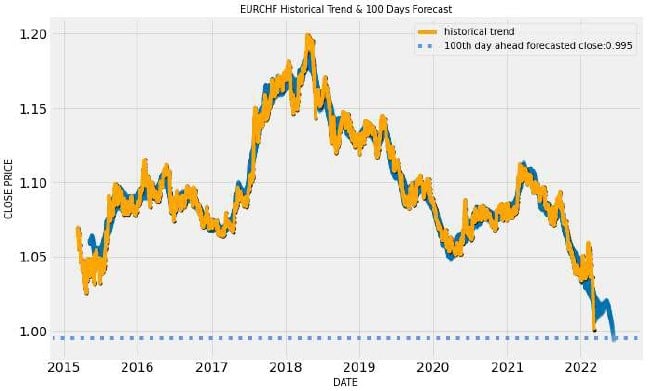
Possiamo a questo punto azzardare anche una previsione a 100 giorni semplicemente cambiando il parametro n_forecast, ottenendo con la stessa serie di istruzioni per il plotting in figura 9, che zoommato dà il grafico di figura 10.
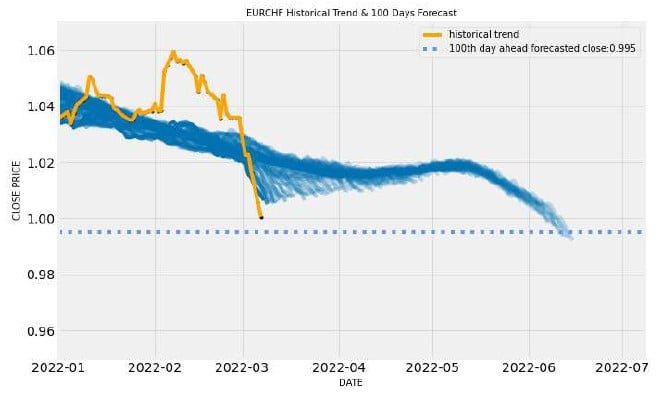
Conclusioni
A proposito di futuro, si pensa che in 50 anni le capacità di calcolo delle macchine saranno notevolmente superiori alla capacità di computazione umana; tra questi c’è chi pensa che questa sia un’opportunità e chi la pensa come minaccia. La macchina dovrebbe in teoria sostituire l’uomo nelle cose che la macchina riesce a fare bene (calcoli, gestione dei dati) ma quando lo sostituisce nelle attività comuni (la guida autonoma) o semplici (servire il caffè o fare il check in di un hotel o gestire una macchina per la pulizia della pavimentazione di un aeroporto o di un centro commerciale) entriamo in un aspetto che ricorda la rivoluzione industriale. Come ricollocheremo gli addetti ai milioni di posti di lavoro che oggi sono impiegati in quei settori occupati da personale in obsolescenza?
Per prevedere questo ora credo che le macchine non possono aiutarci, perché quando entriamo nel campo della fantasia e creatività forse siamo ancora superiori e ancora per un po’ irraggiungibili.
Siamo meno dipendenti da dati di input delle macchine perché abbiamo immaginazione, abbiamo ispirazione, abbiamo sensazioni. Non confondiamo la capacità di progredire con la semplice capacità di fare previsione. Ricordiamo che alla base dell’intelligenza artificiale c’è l’idea di trovare dei pattern storici semplicemente sulla base di un enorme quantità di dati. In passato facevamo previsioni dopo aver compreso il fenomeno oggetto di studio ma le stesse non erano accurante quanto quelle che facciamo oggi con AI. D’altra parte possiamo affermare che l’algoritmo, pur analizzando bene i dati e le correlazioni, non comprende in maniera intelligente e consapevolmente quello che sta facendo. Tuttavia un sistema a guida autonoma riesce a decidere razionalmente, sulla base della sua codifica se in una situazione di pericolo deve proteggere i suoi passeggeri, e il bambino che attraversa la strada. E se fosse un ladro che scappa? C’è un grande dibattito sull’etica dei sistemi AI e sulla responsabilità dei vari attori, a partire dai softwaristi agli utilizzatori, fino a quella dello stesso sistema. Insomma è un mondo che diventa sempre più complesso.
Con questo articolo chiudiamo un primo ciclo di studio degli algoritmi di machine learning. Nella prossima uscita faremo un esercizio sulla applicazione di algoritmi di elaborazione automatiche per analisi tecnica.
Per chi fosse interessato ad ottenere il codice completo e strutturato per un plug and play in ambiente Jupiter Notebook, richiedetelo pure all’autore all’indirizzo email nicola.matarese73@gmail.com.
 |
Nicola Matarese Classe 1973, ha conseguito una laurea magistrale in ingegneria meccanica ed ha ricoperto ruoli manageriali all’interno di realtà industriali in ambito aerospazio e difesa. È appassionato di trading e opera sui mercati dal 2001. Da qualche anno lavora a sistemi di trading supportati da teorie sui Big Data e Intelligenza Artificiale. |
[1] I sei steps di un codice ML:
- Importazione e lettura dati
- Elaborazione, trasformazione e organizzazione dati
- Definizione del modello da utilizzare
- Addestramento del modello
- Valutazione dell’affidabilità del modello
- Previsione
[/wcr]




{kind=link}